相似问句识别在社区问答系统和检索式问答系统中占有重要地位。相似问句识别(问句匹配)的目的是判断两个问句的语义是否等价,在问答系统中相似问句识别主要通过计算问句语义相似度来实现,因此相似问句识别任务是一种短文本语义相似度计算。微调BERT在多个任务上取得了很好的效果,但对于相似问句识别任务仍有改进的地方,一是 BERT 作为一种通用模型对所有序列匹配任务都使用Softmax函数进行输出,没有对相似问句识别任务进行特定的建模。二是在序列匹配任务上微调时仅利用了[CLS]位置的输出向量,忽略掉了其他位置的编码信息。在相似问句识别任务中,其他位置的编码信息也包含了丰富的语义信息。针对上述的问题本章利用BiLSTM-RCNN模型对BERT的输出进行特征提取,弥补了BERT采用统一的Softmax 函数对进行预测输出的缺陷,也将其他位置的编码信息利用起来。
由于BERT模型有着强大的文本表征能力,所以我们在相似问句识别任务上对BERT模型进行微调。但BERT微调方法仅仅使用了[CLS]位置的语义向量,忽略了其他位置的输出向量,并且仅利用Softmax函数对BERT的输出进行计算。为了解决这些问题,我们提出了基于BERT-RCNN的相似问句识别模型,模型结构如图1所示。
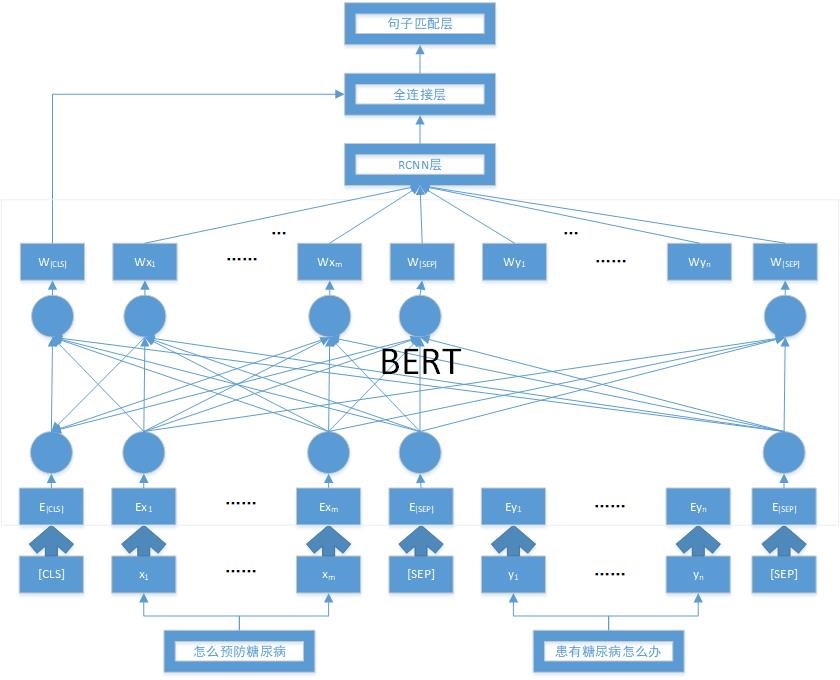
图1 基于BERT-BiLSTM-CNN的相似问句识别模型
循环神经网络是处理序列问题最常用、最有效的方法。通过隐藏层节点之间的相互连接,将前面的信息记忆应用到当前的输出中,以实现捕捉上下文信息的目的。但是,训练过程中会出现梯度消失和梯度爆炸的问题,因此只能捕捉少量的上下文信息。LSTM网络利用不同的函数处理隐藏层的状态,实现对重要信息的筛选,能很好地解决梯度问题,捕捉更多的上下文信息,是当前文本处理的主流方法。
卷积神经网络通过固定大小的卷积核提取文本局部信息,用池化层减少数据处理量并保留关键的信息。因为卷积核是一个固定的窗口,所以同时可能会丢失一些重要的信息,虽然可以通过多个不同大小的窗口来弥补信息缺失,但是会增大计算量,并且不能捕捉上下文信息。
本文方法结合LSTM网络能捕捉更多上下文信息和CNN网络能保留关键信息的特点,首先利用双向LSTM网络提取单词的上下文信息;然后利用1D卷积神经网络将上下文信息与词嵌入信息进行信息融合;最后通过全局最大池化提取关键信息。
将上述模型定义为BERT-RCNN,下面介绍具体过程。
1 BERT层
设两个问句分别为X=x1,…,xm,Y=y1,…,yn。BERT模型的输入需要利用[CLS]和[SEP]将问句X,Y拼接为一个序列,将序列I中的每个字符分别编码为词量,段向量和位置向量,然后依据这三个向量得到BERT输入向量S,通过BERT对S进行编码得到序列的向量表示。
2 RCNN层
(1) 双向LSTM网络提取上下文信息
BERT层得到问句序列通过双向LSTM网络提取上下文信息之后,将上下文信息与词嵌入信息进行拼接得到此时问句词序列中词的语义表示。
(2) 1D卷积进行信息融合
利用1D卷积神经网络对拼接之后的词序列语义表示进行融合
(3) 最大池化提取关键特征信息
为提取文具中的关键特征信息,采用全局最大池化,即取每个序列特征在单个维度上的最大值,提取出关键特征信息,即得到整个句子的语义特征表示。
(4) 全连接层和句子匹配层
将RCNN网络输出的句向量S与BERT输出的语义关系向量拼接,然后输入到全连接神经网络,最后进入句子匹配层,利用Softmax函数得到句子相似概率输出。
3 实验
(1) 数据集及评价标准
本项目选用收集的1500个问题集合(这里测试数量仿真医院场景,医院正常实际日均测试数据量达到120-180条),由于分析问题集合发现大部分语句回答和提问都在50词一下,因此讲本项目将问题长度都归为50的长度,然后将这些问题集依次导入问答系统,。
评价指标采用准确率和得分。
(2) 实验结果与分析
验证本项目问题相似度计算方法的成效,使用了分别和其有类似框架的方式进行对比实验的方法。
首先是CLSTM的网络结构模型参数设置:现将卷积核大小分成1、2、3,再将滤波器设置为256个,其后接上单层LSTM网络,同时隐藏层也和滤波器数目相同。后将3者结合,传入全连接层,其节点数目与上文相同。
本项目参数设置:BERT层中本项目使用微调BERT模型,BERT-Base预训练的模型中的隐藏层设置为768,前部反馈网络设置为3072,设置12个编码器层,多头为12个。RCNN层中将单层LSTM作为循环网络结构,同时将tanh函数作为激活函数;在1D卷积神经网络中,卷积核大小为128,ReLU函数优化算法选择Adam,学习率设置为0.01,MSE作为损失函数,在训练过程中,批处理参数为512,6轮训练。
将各个框架结构的最佳参数设置后,将本数据集按照8:2的比例分割成训练集合与测试集合,将训练集合按照9:1的比例分出验证集合。几种孪生网络框架的实验结果如表1所示
表1 不同方法的实验结果
|
序号 |
方法 |
准确率/% |
得分 |
|
1 |
Siamese-CNN |
79.50 |
- |
|
2 |
Multi-Perspective-CNN |
81.32 |
- |
|
3 |
Siamese-LSTM |
82.57 |
- |
|
4 |
Multi-Perspective-LSTM |
83.20 |
- |
|
5 |
CLSTM |
82.21 |
0.7660 |
|
6 |
LSTM//CNN |
81.43 |
0.7580 |
|
7 |
Bert-RCNN |
84.57 |
0.7852 |
由表1中1和2的数据对比来看我们可以看出使用多视角使用的CNN比单一方式的CNN准确率要高,并且从3和4的数据来看我们可以清楚地得出多视角使用LSTM方法也比单一方式的LSTM方法可靠,并且对比1和3实验数据,本实验中数据集上选择LSTM网络比CNN的网络方式能力更强;另外从全部数据来看,可以看出本项目提出的BERT-RCNN问题相似度的运算方式有着更高的准确性,达到了84.57%。所以,将多种方式融合的方法可以更加有效且准确的将文本信息提取出来,表达的能力同样也会得到增强。
由本项目实验数据的后几项合一看出,本项目采用的模型有较好的实验效果。
针对BERT模型没有对相似问句识别任务建模的问题和序列匹配任务忽略了除[CLS]外其他位置的编码信息问题,可利用BiLSTM-RCNN模型对BERT的输出进行特征提取,弥补了BERT采用统一的Softmax 函数对进行预测输出的缺陷,也将其他位置的编码信息利用起来,根据实验结果显示先使用bert,后使用双向LSTM提取信息并和嵌入层相结合,之后再将信息融合于1D卷积层的方式有着相比较好的实验效果。与此同时,在对应的实验中发现了1D卷积层可以将特征信息融合和降维,使得该方法有着更好的实时性。
参考文献
[1] Saeedi P, Salpea P, Karuranga S, et al. Mortality attributable to diabetes in 20–79 years old adults, 2019 estimates: Results from the International Diabetes Federation Diabetes Atlas[J]. Diabetes research and clinical practice, 2020, 162: 78-108.
[2] Xu Y, Wang L, He J, et al. Prevalence and control of diabetes in Chinese adults[J]. Jama, 2013, 310(9): 948-959
[3] Liu Y, Xiao X, Sun C, Tian S, Sun Z, Gao Y, et al. Ideal glycated hemoglobin cut-off points for screening diabetes and prediabetes in a Chinese population. J Diabetes Investig. 2016 Sep; 7(5): 695-702.
[4] Contreras I, Vehi J. Artificial intelligence for diabetes management and decision support: literature review[J]. Journal of medical Internet research, 2018, 20(5): 1-5
[5] 杨德志,柯显信,余其超,杨帮华,基于RCNN的问题相似度计算方法[J],计算机工程与科学,2019,43(06):1076-1080.
(2022-12-17 08:00:00)
- 政府
- 上级指导单位
