自动驾驶的发展,在人工智能等技术的推动下,有了极大的进步,而感知系统是自动驾驶的重要基础与先决条件,其主要负责的工作包括车道线检测,目标检测和语义分割任务等。今天,我们就来重点学习一下感知系统中目标检测任务的技术细节吧。

自动驾驶的车辆自主行驶在道路上时,需要对周围三维的场景进行感知,而三维的目标检测用于获取三维空间中的位置和类别信息,是自动驾驶感知系统中的基础,也是其下游任务——路径规划、运动预测、目标跟踪的基础。在无人车上,一般配置有多种类型的传感器来感知环境,如单目摄像头和激光雷达等,根据使用传感器类型的不同,三维目标检测可以分为基于图像,点云和多模态数据融合等方式。接下来我们对上述三种目标检测方法,一一介绍其代表性工作。
1、基于图像的三维目标检测
由于2D的目标检测任务相对于3D目标检测来说,发展较为成熟且已有不少被证明有效的方法,所以一个直观的想法就是将2D上的框架迁移至3D的任务上,下面介绍的FCOS3D则是其中一篇工作。
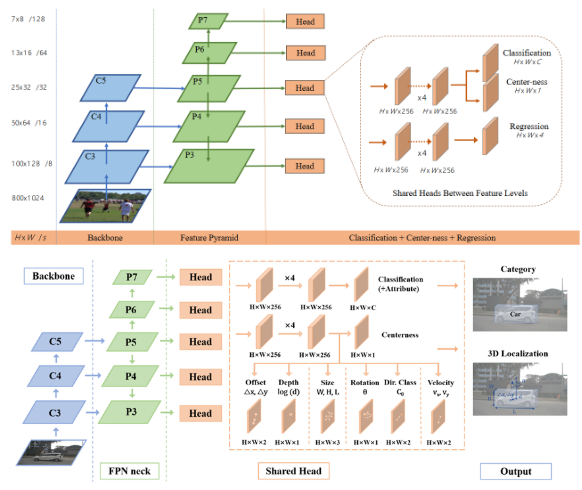
图 1 上图为FCOS框架,下图为FCOS3D框架
可以看出,FCOS3D整体的pipeline和2D的FCOS没有太大的区别,同样采用了先对图像使用如ResNet的backbone网络提取特征,而后经过FPN结构对提取的特征进行多尺度特征的进一步提取,经过FPN提取后的多尺度特征,分别通过检测头来预测目标的属性。在2DFOCS中,检测头直接预测的属性为当前特征点映射回原图点中,所代表点距离预测框四边的距离(l,t,r,b)及其预测框代表的类别信息(class_label)。

图 2 FCOS2D预测信息
而在FCOS3D中,由于需要预测3维的检测框,则其预测属性调整为其特征点映射回原图点中,所代表点距离目标框中心的偏移量(∆x,∆y)及距离无人车坐标系下的深度(d),3D目标检测框的长宽高(w,h,l),以及3D目标检测框的角度,方向和速度信息(angle,dir,vel)。通过简单的调整检测头的输出信息,将2D目标检测中应用成熟的框架迁移至3D目标检测任务中,也是目前的研究热点之一。
2、基于点云的三维目标检测
激光雷达获取的信息可以用点云的形式进行存储,一个点云中的点除了包含X,Y,Z坐标以外,还包含反射强度r。其相对于图像信息而言,拥有深度信息的优势,但如何处理相对稀疏的点云是主流的研究热点。目前来看,根据点云的处理中的表示方法,大致可以分为两类:基于体素(voxel-based)的方法和基于点(point-based)的方法,下面介绍的Pointpillars则是基于体素的方法中兼具速度和性能的方法之一。
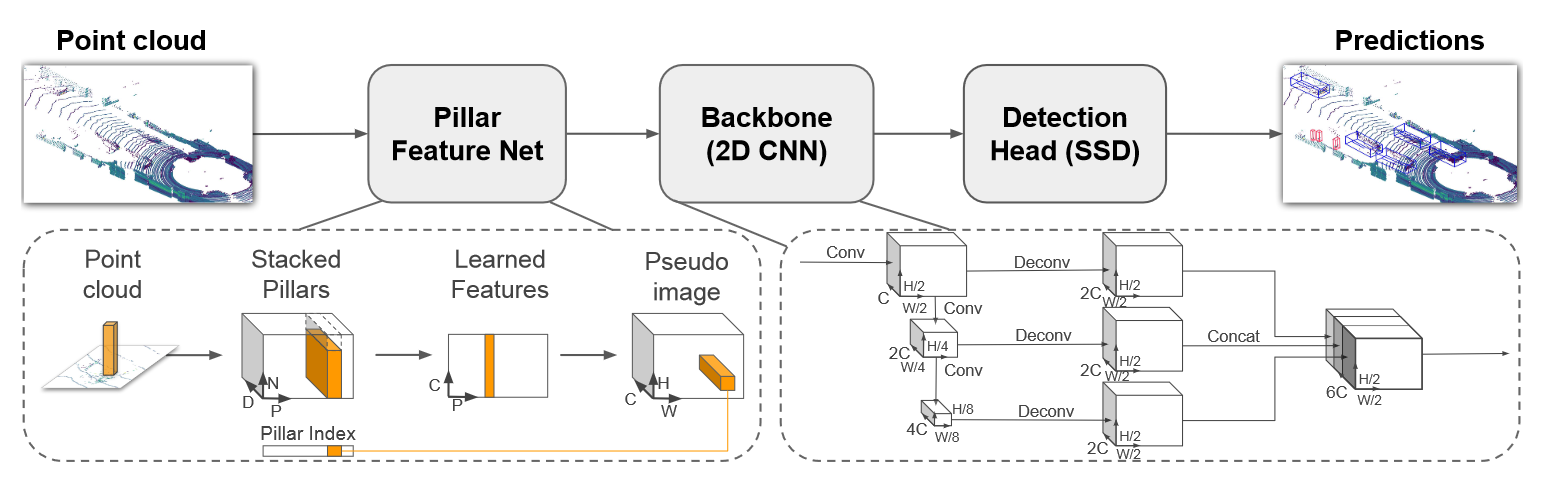
图 3 Pointpillars框架
其核心思想是将点云数据划分为一个个体素(voxel)中,将不规则的点云信息,构成规则密集分布的体素集合。其中每个体素中的点可以用一个9维的向量来进行表示(x,y,z,r,x_c,y_c,z_c,x_p,y_p),其中(x_c,y_c,z_c )为点云所在体素的中心坐标,其中x_p=x-x_c,y_p=y-y_c反应了点云与其体素中心坐标的相对关系。由此我们就实现了点云的张量化,根据坐标信息,整幅点云信息可以张量化为(D,P,N)的向量,其中D=9,P=P_x⁄v_x , N=P_y⁄v_y ,P_x和P_y代表点云x轴方向和y轴方向的范围,v_x和v_y则代表每个voxel在x轴和y轴方向的大小。得到(D,P,N)的向量后,我们使用处理点云数据常用的PointNet网络,可以提取出(C,P)的特征,而后将P表示为(H,W)的形式,则得到了由点云表示的伪图像信息,后面就可以利用三维图像处理方法来进行处理,获得3D的目标检测框。
在近几年有关点云的研究中,越来越多的模型方法并没有明确的界限划分,而随着Transformer的火热,最近有很多论文尝试把Transformer的结构或者思想引入点云3D检测中,如Voxel Transformer和SST等。
3、基于图像和点云的多模态融合方法
多模态融合的方法中,主要要解决以下三大问题:传感器视角问题,数据表征不一致问题,信息融合结构的难度问题。在传感器视角问题上,由于图像信息是通过摄像头根据小孔成像原理,是从一个视锥出发获取的信息,而点云信息则是从3D真实世界获取的信息,这使得两者的视角表征不一致在数据表征问题上,图像信息是密集的规则的,而点云信息是相对稀疏和不规则的,如何在特征层或者输入层进行信息融合是一个需要处理的问题在信息融合结构问题上,传统的深度学习方法,通常均用CNN的方法来处理图像,由于点云的数据特殊性,并不能直接采用CNN的方法来进行处理,故以何种结构来进行信息融合,也是其难点之一。在最近的研究中,研究员发现在bird’s-eye view(BEV)的视角下,进行信息融合可以很好保留空间和语义信息,实现性能的大幅提升,其中的代表工作为下文介绍的BEVFusion。
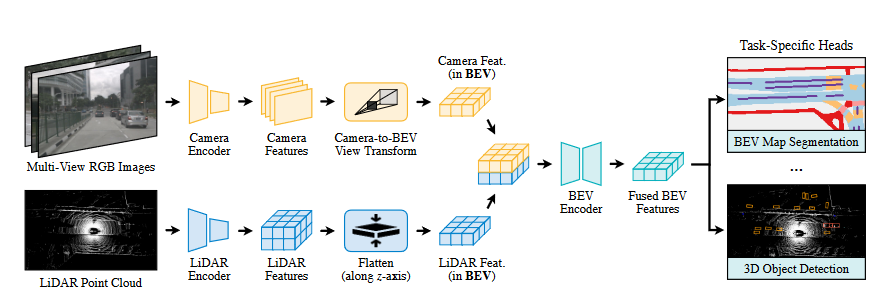
图 4 BEVFusion框架
有关BEV视角下的特征表示,由于点云数据自带的3D特征,其表示为BEV视角只需通过简单的旋转变换即可完成,此工作主要解决的问题在于如何高效的将图像特征也表示在BEV视角下。作者在此处设计了一个网络来学习BEV View Transform来完成特征到BEV视角的转变,其实质在于去预测特征图上每个像素的深度信息,则(N,H,W)的图像特征可以被表征为(N,H,W,D)的特征,而后通过将特征在z轴方向展平,则可获得图像信息在BEV视角下的表示。有了图像和点云在BEV视角下的特征表示,将两者拼接起来后接上检测头,则可以获得预测输出。此方法得益于BEV视角下的优越性,引领着新一轮多模态融合框架的发展。
参考文章
Wang, Tai, Xinge Zhu, Jiangmiao Pang, and Dahua Lin. ‘FCOS3D: Fully Convolutional One-Stage Monocular 3D Object Detection’. arXiv, 24 September 2021. http://arxiv.org/abs/2104.10956.
Tian, Zhi, Chunhua Shen, Hao Chen, and Tong He. ‘FCOS: Fully Convolutional One-Stage Object Detection’. arXiv, 20 August 2019. https://doi.org/10.48550/arXiv.1904.01355.
Lang, Alex H., Sourabh Vora, Holger Caesar, Lubing Zhou, Jiong Yang, and Oscar Beijbom. ‘PointPillars: Fast Encoders for Object Detection from Point Clouds’. arXiv, 6 May 2019. https://doi.org/10.48550/arXiv.1812.05784.
Liu, Zhijian, Haotian Tang, Alexander Amini, Xinyu Yang, Huizi Mao, Daniela Rus, and Song Han. ‘BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird’s-Eye View Representation’. arXiv, 16 June 2022. https://doi.org/10.48550/arXiv.2205.13542.
(2022-11-12 11:30:57)
- 政府
- 上级指导单位
