一、 概述
人脸识别其实很早就有了,随着人工智能的火热,计算能力、模型等的推进,使得人脸识别产品在识别精度、速度、用户友好度等多个方面都有明显提升,今天我们就简单介绍一下人脸识别的基本原理。
人脸识别通常分为两大类:一类是确认,这是人脸图像与数据库中已存的该人图像比对的过程,回答你是不是你的问题。一类是辨认,这是人脸图像与数据库中已存的所有图像匹配的过程。显然,人脸辨认比人脸确认要难,但是无论哪类,都主要分为人脸检测、特征提取和人脸识别三个过程。

二、 人脸识别流程
1、 图像表示
了解人脸识别,先要从图像表示开始讲起。计算机能够识别和处理的是二进制数据,不管我们输入的是文本、图像还是声音,计算机都是用一定长度的二进制串进行存储和处理我们先以黑白图片为例,看看计算机是怎么表示的。
计算机程序可以将黑白图片表示为灰度图像。在灰度图像中,一个像素使用8个比特位,从而可以表示256个灰度值,表示范围是0-255.其中0代表纯黑色,255代表纯白色,一个字节可以表示一个像素,这样我们就可以用一个矩阵来表示一张图片。
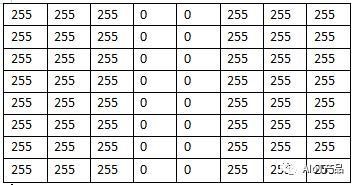
像上面这张图片,就可以表示成为数字1.
2、 找出所有的面孔
很显然我们在进行人脸识别的过程的第一步,是先找出照片中所有的人脸,那我们该如何找出图片中的人脸呢?为什么手机拍照中的人像模式能轻松的找出人脸的位置呢?下面我们来介绍一下它的基本原理。
这里我们得感谢Paul Viola和Michael Jones在2000年发明了一种能够快速在廉价相机上运行的人脸检测方法,人脸检测在相机上的应用才成为主流。然而现在我们有更可靠的解决方案HOG(Histogram of Oriented Gradients)方向梯度直方图,一种给能够检测物体轮廓的算法首先我们把图片灰度化,因为颜色信息对应人脸检测而言没什么用,首先要通过某种方法来显示图像从明亮到灰暗流动的过程,我们可以将图像分割成16*16的小块,根据明暗度在小方块处画一个箭头,箭头的指向代表了像素逐渐变暗的方向,这些箭头被成为梯度,最终,我们就可以把原始图像转换成一个非常简单的HOG表达形式,它可以很轻松的捕获面部的基本结构。
为了在HOG图像中找到脸部,我们需要做的是,与已知的一些HOG图案中,看起来最相似的部分,这些HOG图案都是从其他面部训练数据中提取出来的。
3、 脸部的不同姿势
我们已经找出来图片中的人脸,但图片中的人脸并总是正面朝向我们的,那我我们如何适当的调整图片中的人脸,来使得眼睛和嘴总是和被检测的图片重叠呢?
为了达到我们的目的,我们有很多算法可供选择,这里我们将使用一种由Vahid Kazemi和Josephine Sullivan在2014年发明的一种面部特征点估计的算法,这一算法的基本思路是找到人脸上普遍存在的68个点(特征点),

有了着68个点,我们就可以知道眼睛和嘴巴在哪了,然后我们将对图片进行旋转、缩放和错切,使得眼睛和嘴巴尽可能的靠近中心。
现在人脸基本上对齐了,这使得下一步更加准确
4、 给脸部编码
我们还有一个核心问题没有解决,那就是如何区分不同的人脸。人类可以通过眼睛大小,头发颜色等等信息轻松的分辨出不同的两张人脸,但是计算机要怎么才能分辨呢?最有效的方法就是让计算机自己找出它要收集的测量值,深度学习比人类更懂得那些面部测量值更重要,因此,我们可以训练一个深度卷积神经网络,训练让它为脸部生成128个测量值。
训练的流程大致如下,我们需要加载一张已知的人的面部训练图像,加载一张同一个人的另一张照片,加载一张另外一个人的照片,然后,算法查看它自己为这三张图片生成的测量值,再稍微调整神经网络,以确保第一张和第二张生成的测量值接近,而第二张和第三张生成的测量值略有不同。我们需要不断调整样本,重复以上步骤上百万次,这属实是一个巨大的挑战,但好在前人们已经做完了这些并发布了几个训练过可以直接使用的网络,不需要我们部署复杂的机器学习。
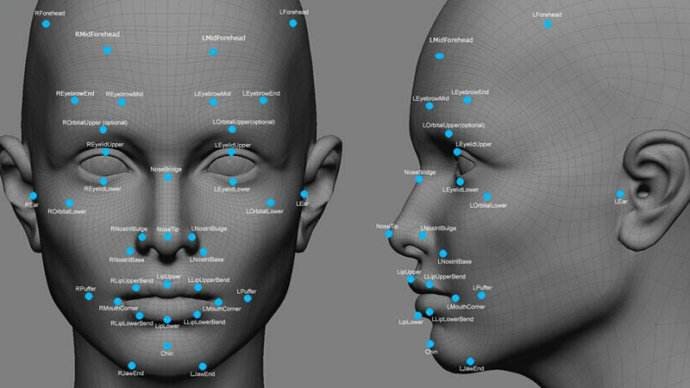
知道这128个测量值之后,我们便可利用一些现成的数学公式,来计算两张图像这128个值的欧式距离。这样我们通过计算得到的欧式距离值和系统给定的阈值进行比对,便可辨别两张图像上的人脸是否是同一个人。
(2022-10-22 10:34:43)
- 政府
- 上级指导单位
